
考考大模型视频理解能力,中科院人大百川提出新基准合成框架
测试Gemini1.5 Pro、GPT-4o等多模态大模型的新基准来了,针对视频理解能力的那种。
直接在视频内容中插入多个无关的图像或文本“针”,严格评估模型对时间理解的能力。
来看下面的栗子。
比如插入密码词“Alice”,让模型找到这个密码词;插入苹果图片,让模型解答这个水果是什么;又或者插入多个“针”,询问模型插入针的顺序是什么。
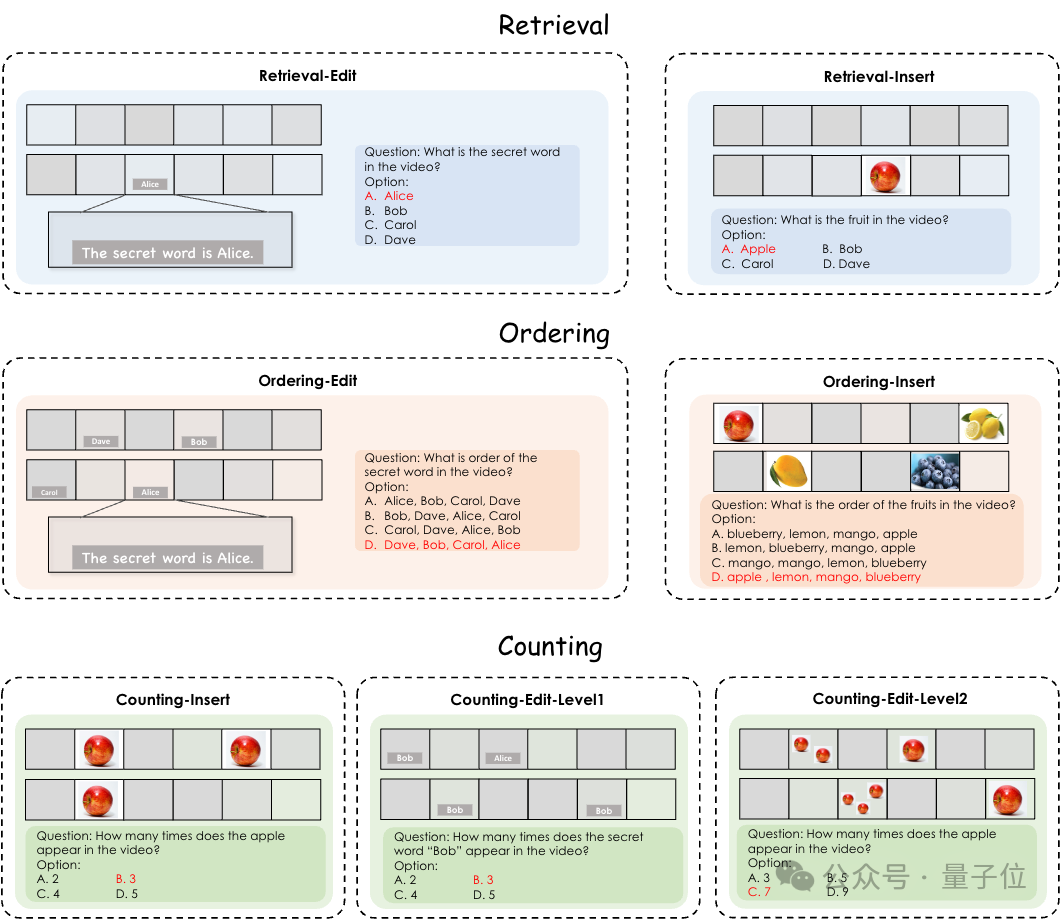
这就是来自中科院、人大、百川的研究团队联合提出的利用合成视频构建视频理解测试基准的方法。
该方法名为VideoNIAH,可以解耦视频内容与其对应的查询-响应对,通过插入无关的图像或文本“针”来生成测试数据,既保证了视频来源的多样性和查询响应的多样性,还通过插入多个针来严格评估模型对时间理解的能力。
此外,使用与现实视频内容相对应的查询-响应对可能存在数据泄露风险,影响基准测试的公平性,使用合成视频生成方法可以有效避免这一问题。
研究团队利用VideoNIAH方法制作了一个能够有效评估视频模型的细粒度理解能力和时空建模能力,同时支持长上下文评估的合成视频理解基准VNBench,包含1350个样本。
随后对Gemini1.5 Pro、GPT-4o、GPT-4-turbo以及其它开源模型进行了测试,并分析了一系列结果。
研究团队发现,即使是GPT-4o等最先进的专有模型,在需要检测和追踪视频中特定空间区域内的“针”等计数任务上的表现也不理想;在排序任务上,专有模型与开源模型之间的性能差距尤为显著……

VNBench更多细节以及更多实验结果我们接着往下看。
用VideoNIAH构建新基准
随着视频中心的MLLMs模型的提出,需要有更全面的基准测试来评估这些模型在视频理解方面的能力,包括细粒度理解、时空建模以及长上下文处理等。
传统的视频基准测试通常需要基于目标能力精心选择视频,并进行繁琐的查询-响应对标注,以匹配特定视频内容。这个过程不仅挑战重重,而且资源消耗巨大。
为了开发和评估视频理解模型,需要一个既能够扩展到不同视频源和长度,又能够高效运行的基准测试框架。
研究团队提出了VideoNIAH。
如前文所述,VideoNIAH(Video Needle In A Haystack)创新性地将测试视频内容与其查询-响应对解耦,通过在原始视频中插入无关的图像/文本“针”(needles),并仅从这些针生成注释。
这种方法不仅确保了视频来源的多样性和查询响应的多样性,还通过插入多个针来严格评估模型对时间理解的能力。
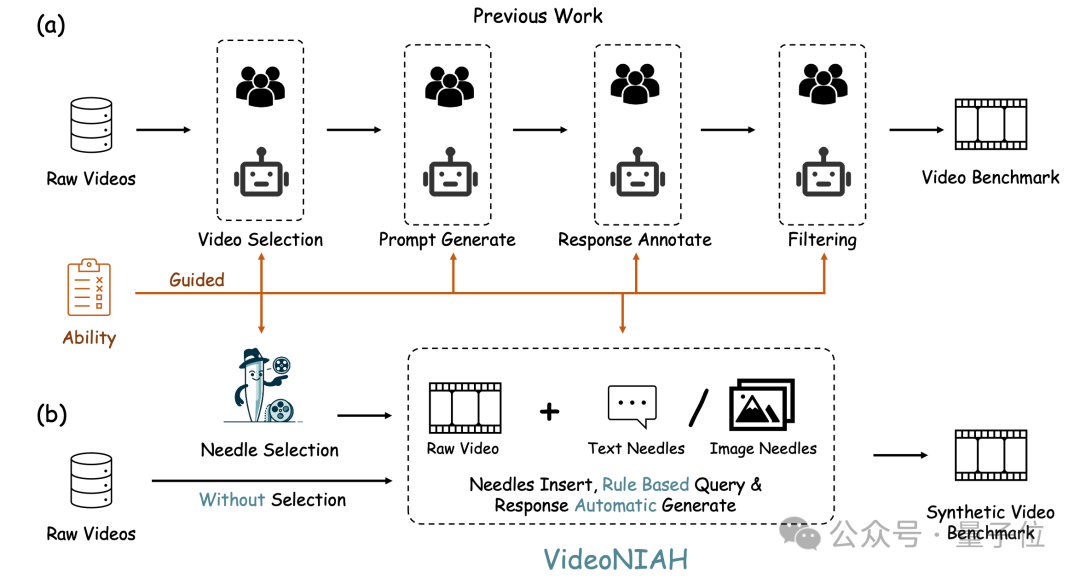
利用VideoNIAH,研究者们构建了一个全面的视频基准测试VNBench,包括检索、排序和计数等任务。VNBench能够有效评估视频模型的细粒度理解能力和时空建模能力,同时支持长上下文评估。
VNBench的特点主要表现在以下三个方面:
“针”类型(Needle Type)的多样性
编辑内帧(Edit):使用人为添加的字幕作为”针”,这些字幕被嵌入到视频帧中,模拟了在视频中寻找特定文本信息的场景。
插入帧间(Insert):使用图像作为”针”,这些图像作为静态片段插入到视频帧之间,考察模型对视频中静态图像的识别和记忆能力。
级别划分:根据图像的可识别性分为两个级别,第一级使用常见物体(如水果图像),第二级使用更具挑战性的地标图像/物体图像,增加了任务的难度。
视频”干草堆”(Video Haystack)的多样性
时间分布:VNBench使用的视频”干草堆”来自不同的数据源,视频时长从10秒到180秒不等,覆盖了短、中、长三种不同的视频长度,以评估模型对不同视频长度的适应能力。
内容覆盖:视频内容包含多种场景,确保了评估的广泛性和视频源的多样性。
查询(Query)的多样性
检索任务:要求模型从视频中检索出特定的”针”,考察模型的细粒度理解和信息提取能力。
排序任务:要求模型识别并排序视频中所有插入”针”的时间顺序,考察模型对视频时间动态和事件序列的理解能力。
计数任务:要求模型计算视频中特定对象的出现次数,包括对单个帧内和跨帧的重复模式的识别和追踪,考察模型在时空维度上的理解能力。
任务分类:VNBench的三个任务类型分别对应不同的视频理解能力评估,检索任务评估信息检索能力,排序任务评估时间推理能力,计数任务评估对视频内容的长期记忆和模式识别能力。
通过这些设计,VNBench能够全面地评估视频理解模型在多样化的视频内容和查询条件下的性能,为视频理解技术的研究提供了一个有力的基准测试工具。
实验及分析结果
在论文中,通过VNBench对视频理解多模态大语言模型(MLLMs)进行了一系列评估,分析结果揭示了以下几个关键点:
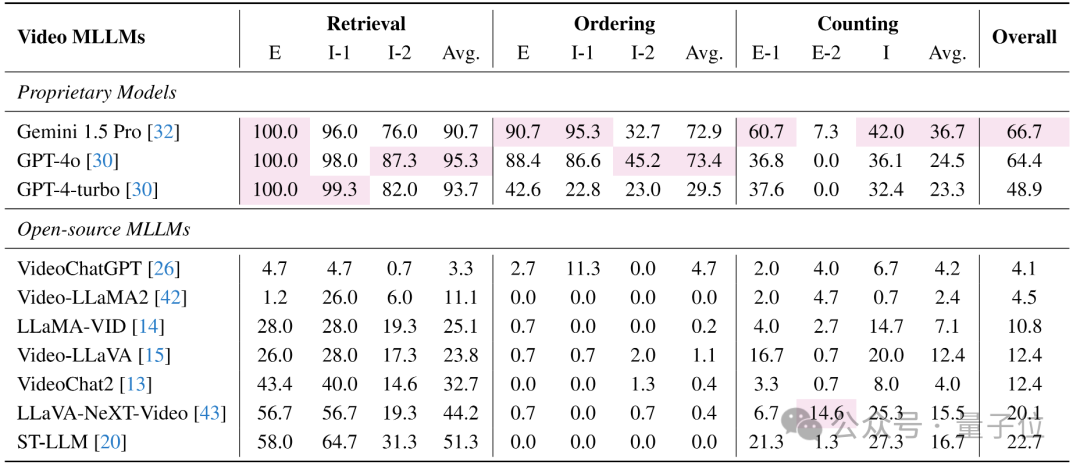
首先是专有模型与开源模型的性能差异。
专有模型(如Gemini 1.5 Pro和GPT-4系列)在大多数VNBench任务上的表现优于开源模型。这表明专有模型可能拥有更优越的视频理解能力,这可能归功于更大的模型参数和更全面的训练过程。
其次是任务难度与模型表现。
模型在单针短依赖任务(检索任务)上的表现普遍优于多针长依赖任务(排序和计数任务)。这表明当前的视频模型在处理需要长期依赖信息的任务时仍然面临挑战。
排序任务的性能差距方面,在排序任务上,专有模型与开源模型之间的性能差距尤为显著。大多数开源模型在排序任务上几乎无法完成任务,这可能是由于它们在训练过程中忽视了时间序列建模的能力。
然后是计数任务的困难。即使是最先进的专有模型,在计数任务上的表现也不理想。特别是在需要检测和追踪视频中特定空间区域内的“针”时(Counting-E-2任务),所有模型的表现都很差,这表明当前的视频模型在理解和建模视频中的细粒度时空关系方面仍有不足。
此外,视频上下文长度的影响方面,随着视频处理时长的增加,开源模型的性能显著下降,而专有模型由于具有更长的上下文处理窗口,性能波动不大。这表明当前模型在处理长视频内容时的能力有限。
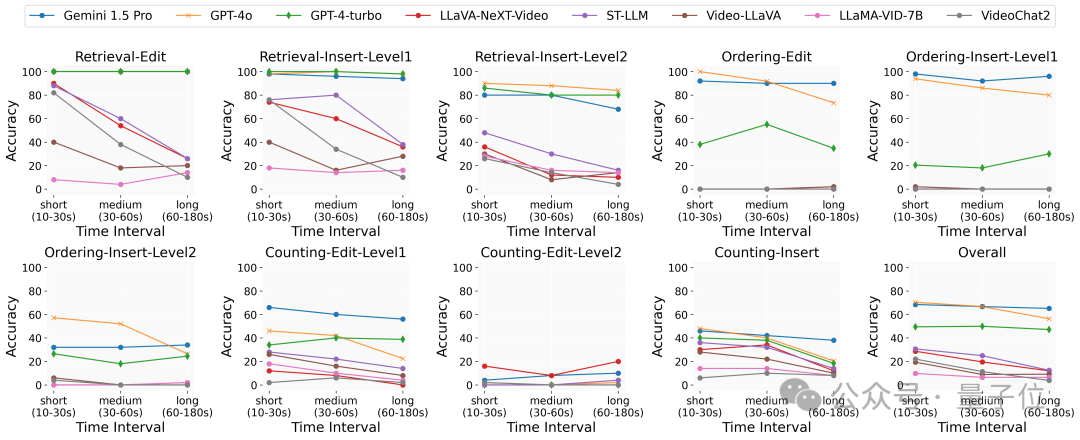
“针”位置的影响方面,通过改变“针”在视频中的位置,研究发现专有模型由于其较长的上下文窗口,能够准确回忆所有插入的信息,而开源模型则表现出在长序列中对中间信息的回忆不足。
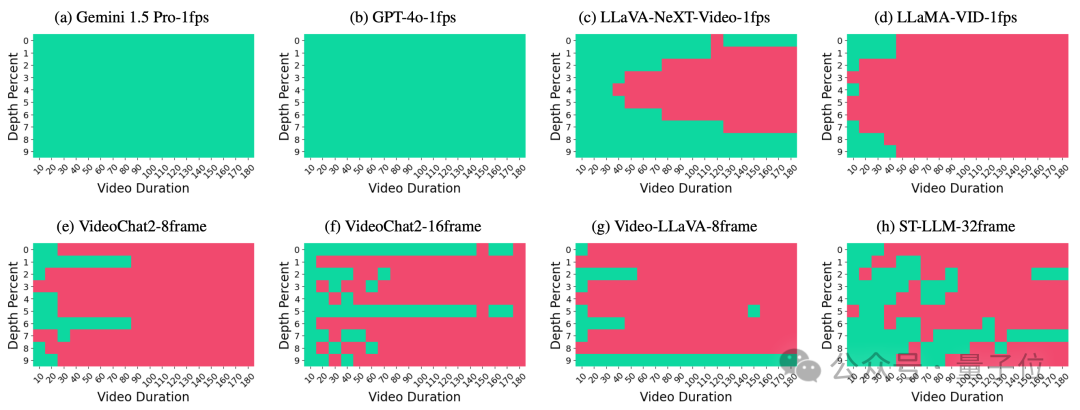
这些分析结果不仅揭示了当前视频理解模型的优势和局限性,而且为未来的研究提供了宝贵的见解,有助于指导视频理解技术的发展和改进。
— 完 —
